
预置工具(私有数据搜索)
| - | 描述 |
|---|---|
| 项目地址 | https://github.com/inf-monkeys/monkey-tools-knowledge-base/ |
| 安装步骤 | 本地部署请见本地部署文档 ; 通过 Helm 部署请见 Helm 部署文档 |
导入此工具
部署完成之后,你需要在执行类工具页面,点击右上角的导入按钮,分别输入此 tools 的 manifest 地址(如 http://localhost:8899/manifest.json)
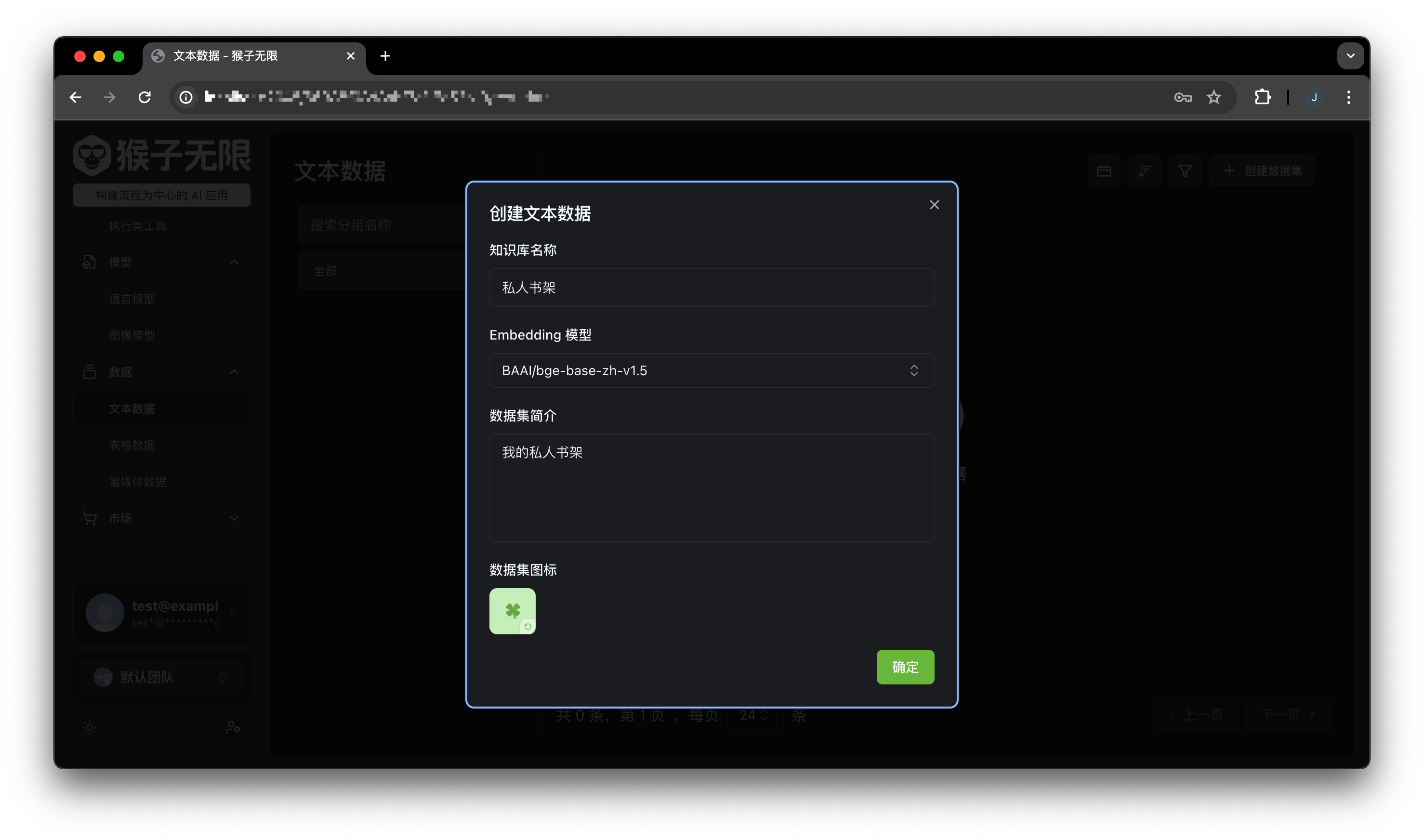
创建文本数据集
在控制台的数据、文本数据页面,点击右上角的创建按钮,填写数据集名称、描述、Embedding 模型,点击创建:
上传文档
这里我们可以使用 https://www.gutenberg.org/browse/scores/top 这个网站下载一些文档,然后上传到我们的文本数据集中。这里我们以 Pride and Prejudice 为例。
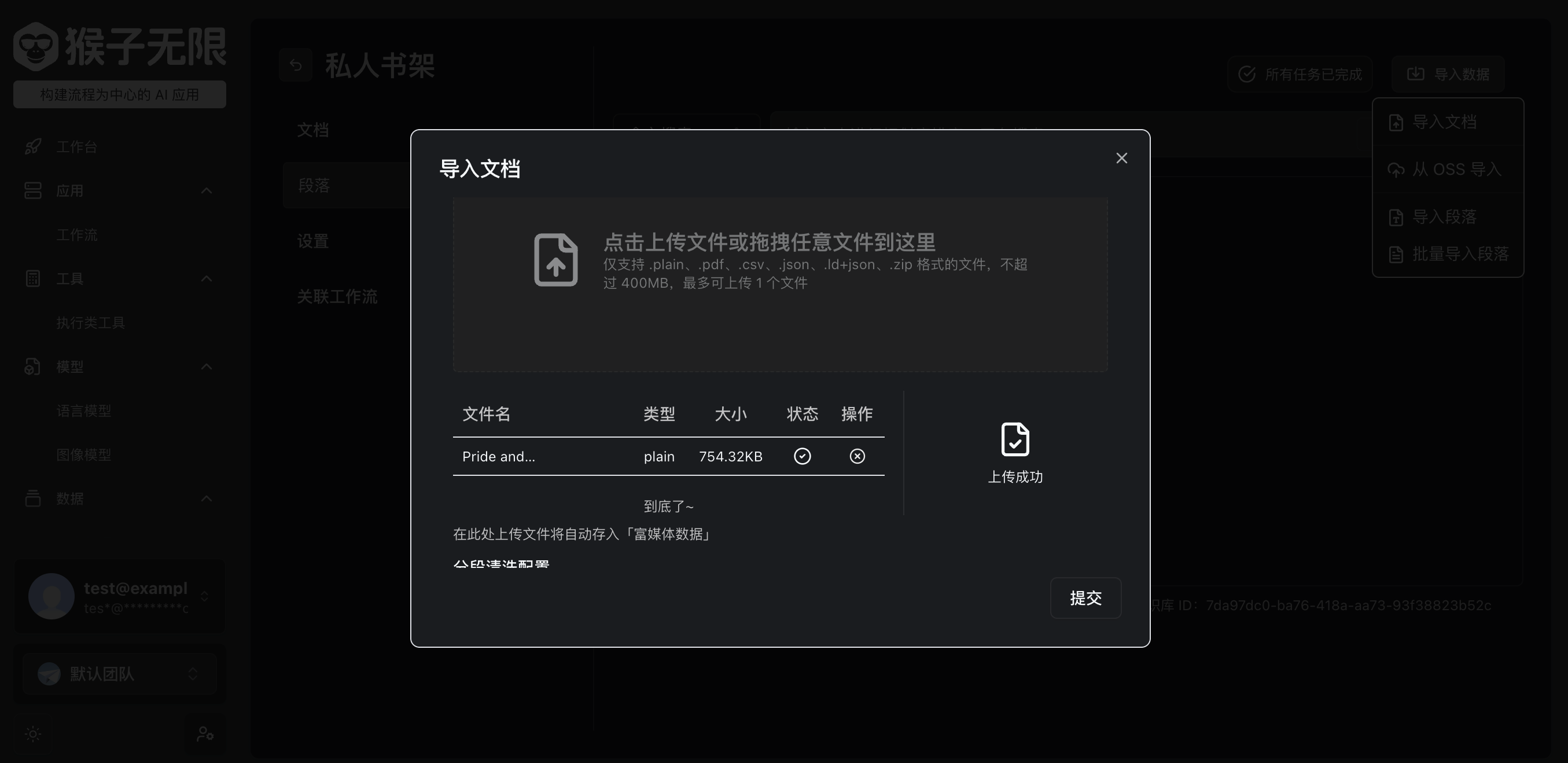
点击提交,等待文档解析、向量化完成。
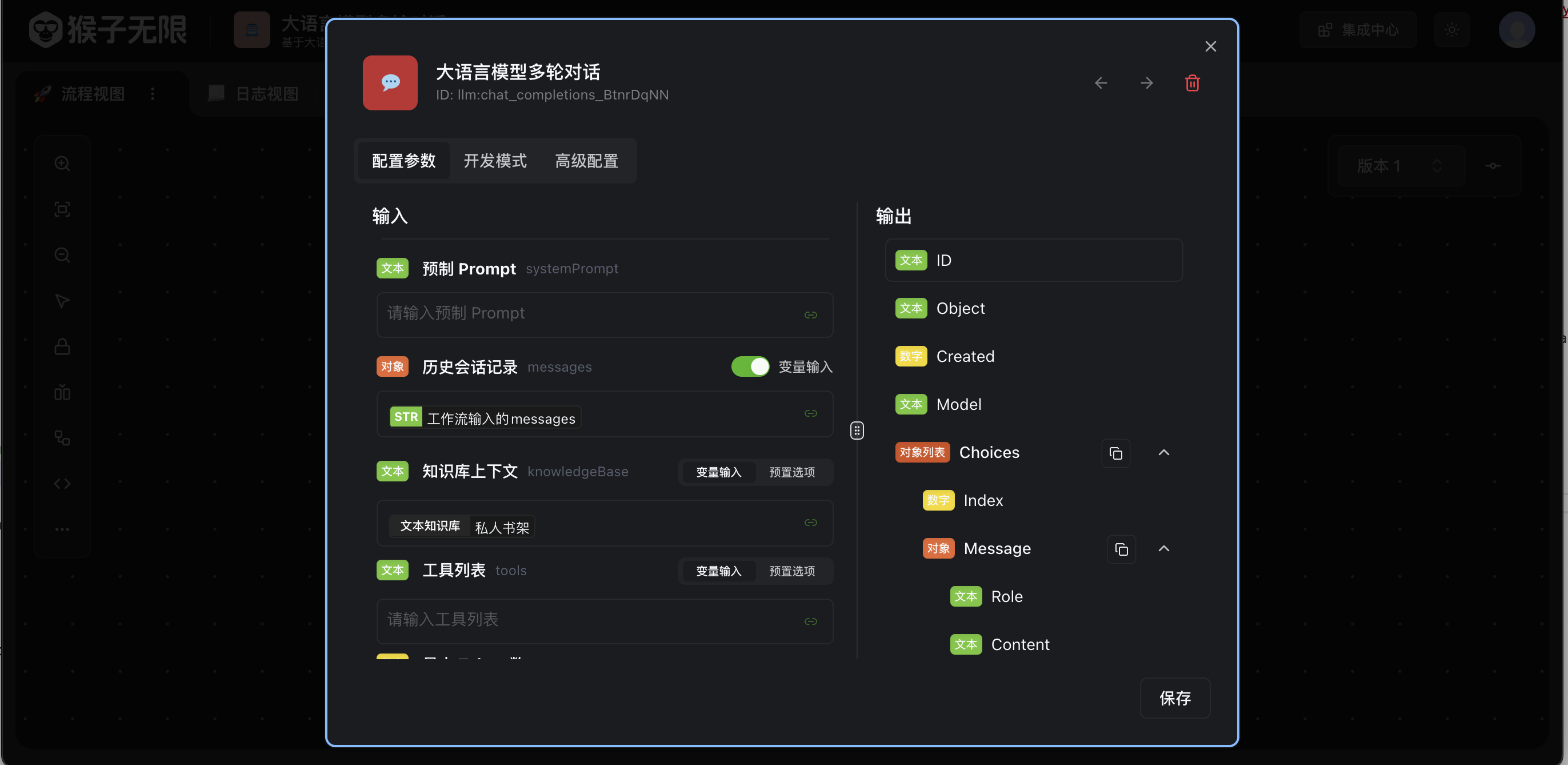
在大语言模型对话
在大语言模型多轮对话工具,点击编辑,在知识库上下文中选择我们刚刚创建的文本数据集并点击保存。
复制工作流详情右上角的集成中心按钮,复制 CURL 命令到终端运行:
curl -X POST 'http://localhost:2048/v1/chat/completions' \--header 'Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxx' \--header 'Content-Type: application/json' \--data-raw '{ "model": "xxxxxxxxxxxxxxxxxxx", "messages": [{"role": "user", "content": "这本书讲的是关于什么 ?"}], "stream": false}'可以看到大语言模型回答的结果:

查看日志,可以看到大语言模型调用了私有数据搜索工具:
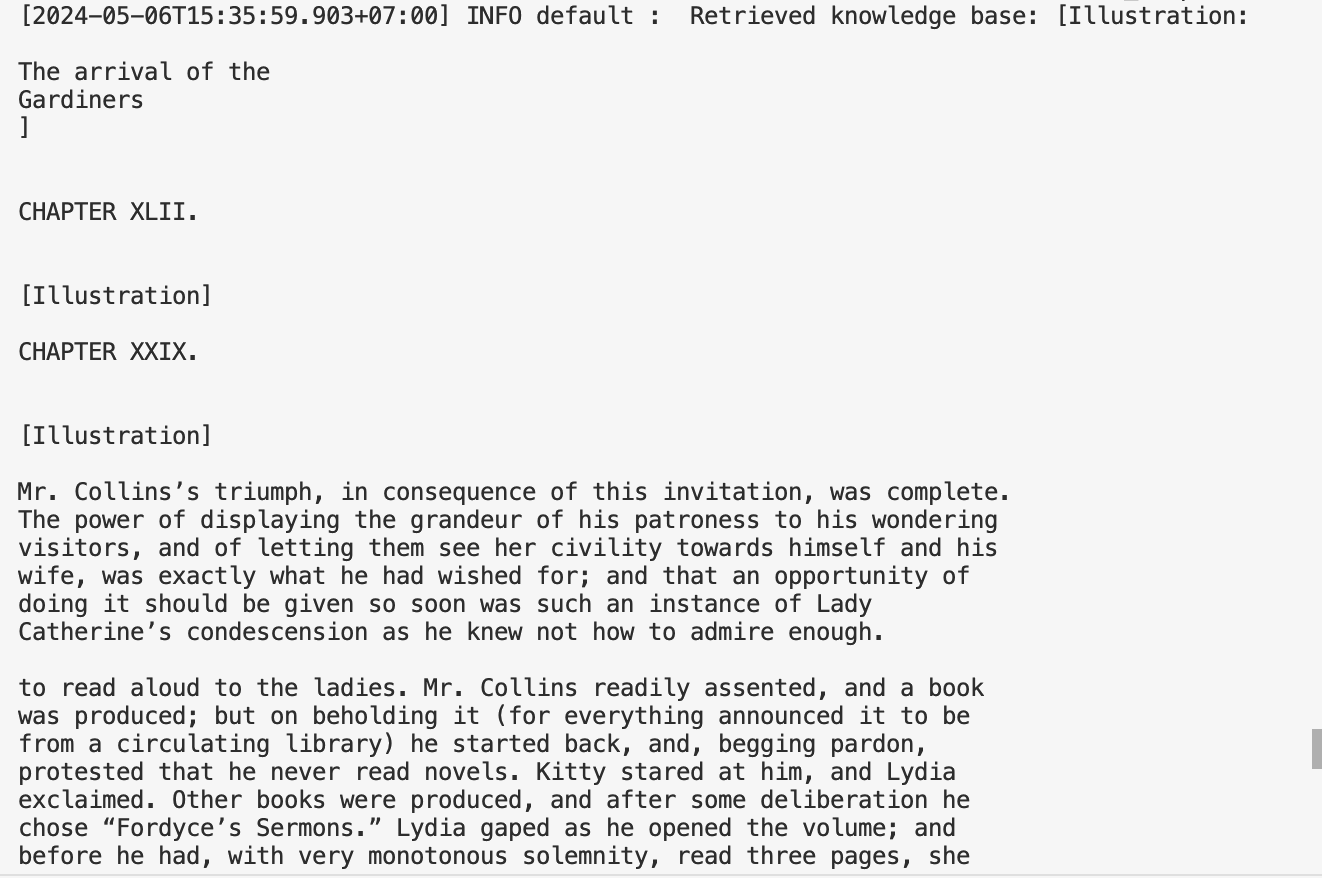
注意:大语言模型回答的质量取决于召回的向量的质量,以及大预言模型本身的能力。