
Built-in Tools (Private Data Search)
| - | Description |
|---|---|
| Project Address | https://github.com/inf-monkeys/monkey-tools-knowledge-base/ |
| Installation Steps | For local deployment, see Local Deployment Documentation; for Helm deployment, see Helm Deployment Documentation |
Importing This Tool
After deployment, you need to go to the Execution Tools page, click the Import button in the upper right corner, and enter the manifest address of this tool (e.g., http://localhost:8899/manifest.json)
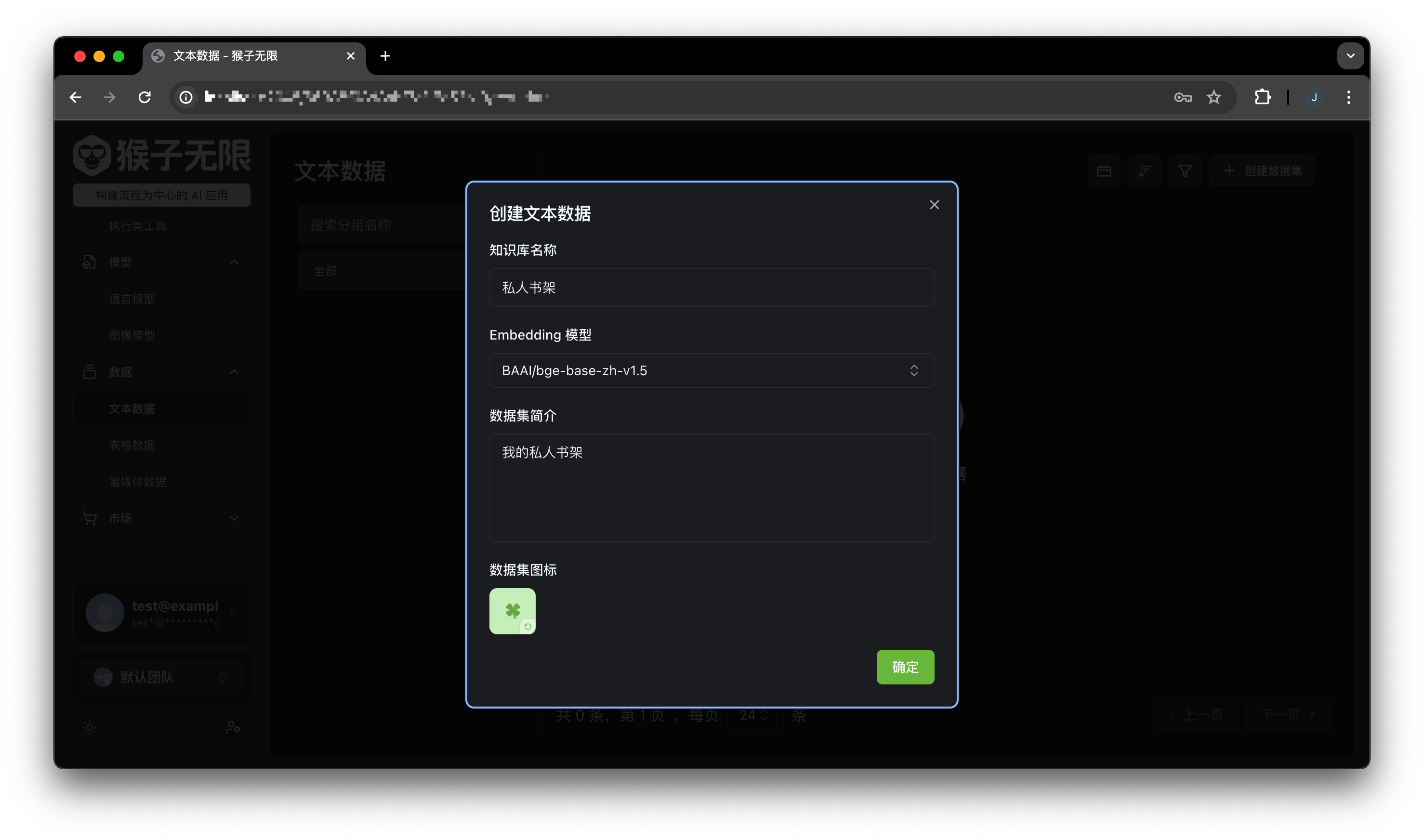
Creating a Text Dataset
In the console’s Data and Text Data pages, click the Create button in the upper right corner, fill in the dataset name, description, and Embedding model, and click create:
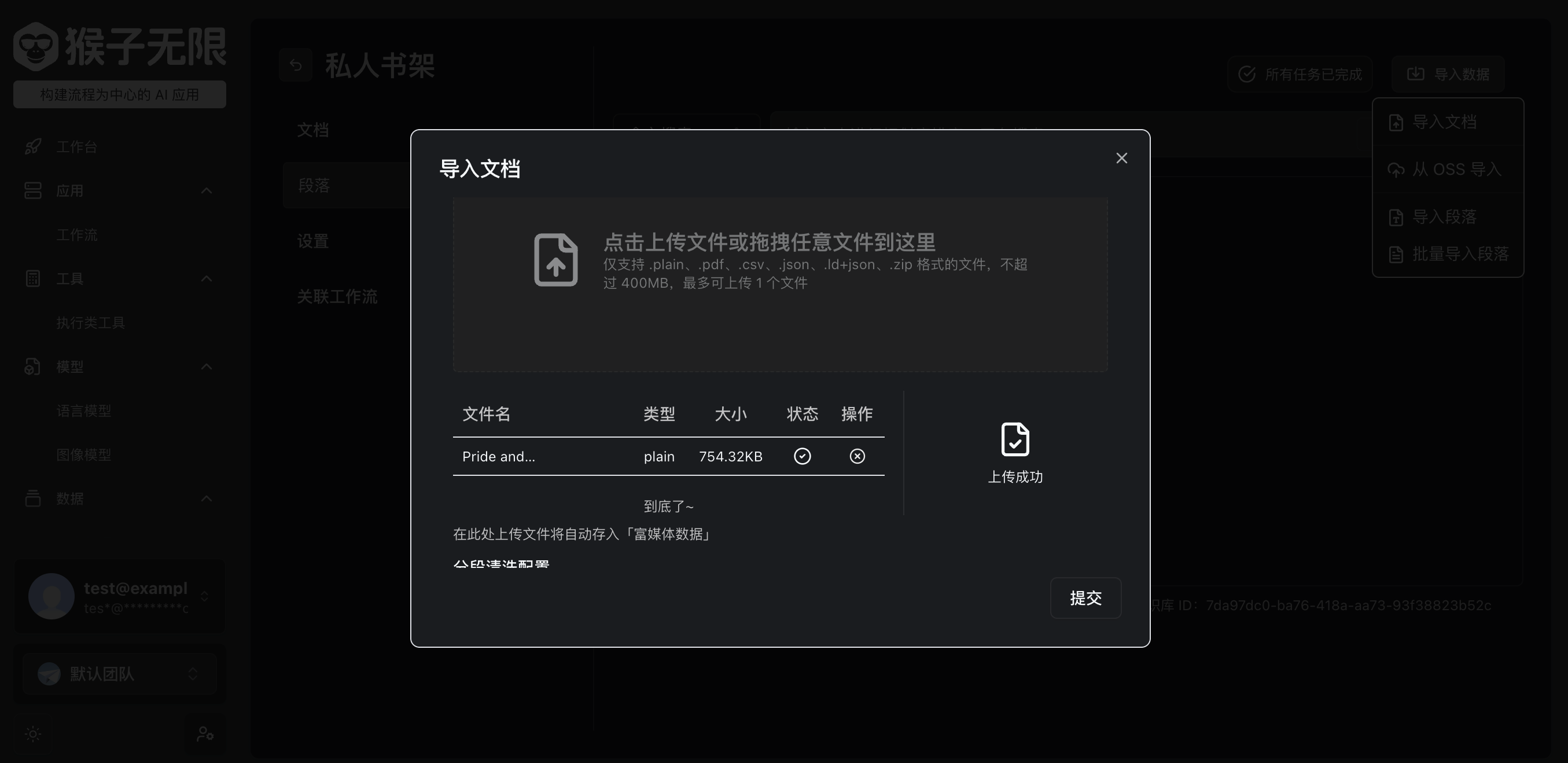
Uploading Documents
Here we can use https://www.gutenberg.org/browse/scores/top to download some documents and then upload them to our text dataset. Here we use Pride and Prejudice as an example.
Click submit and wait for the document parsing and vectorization to complete.
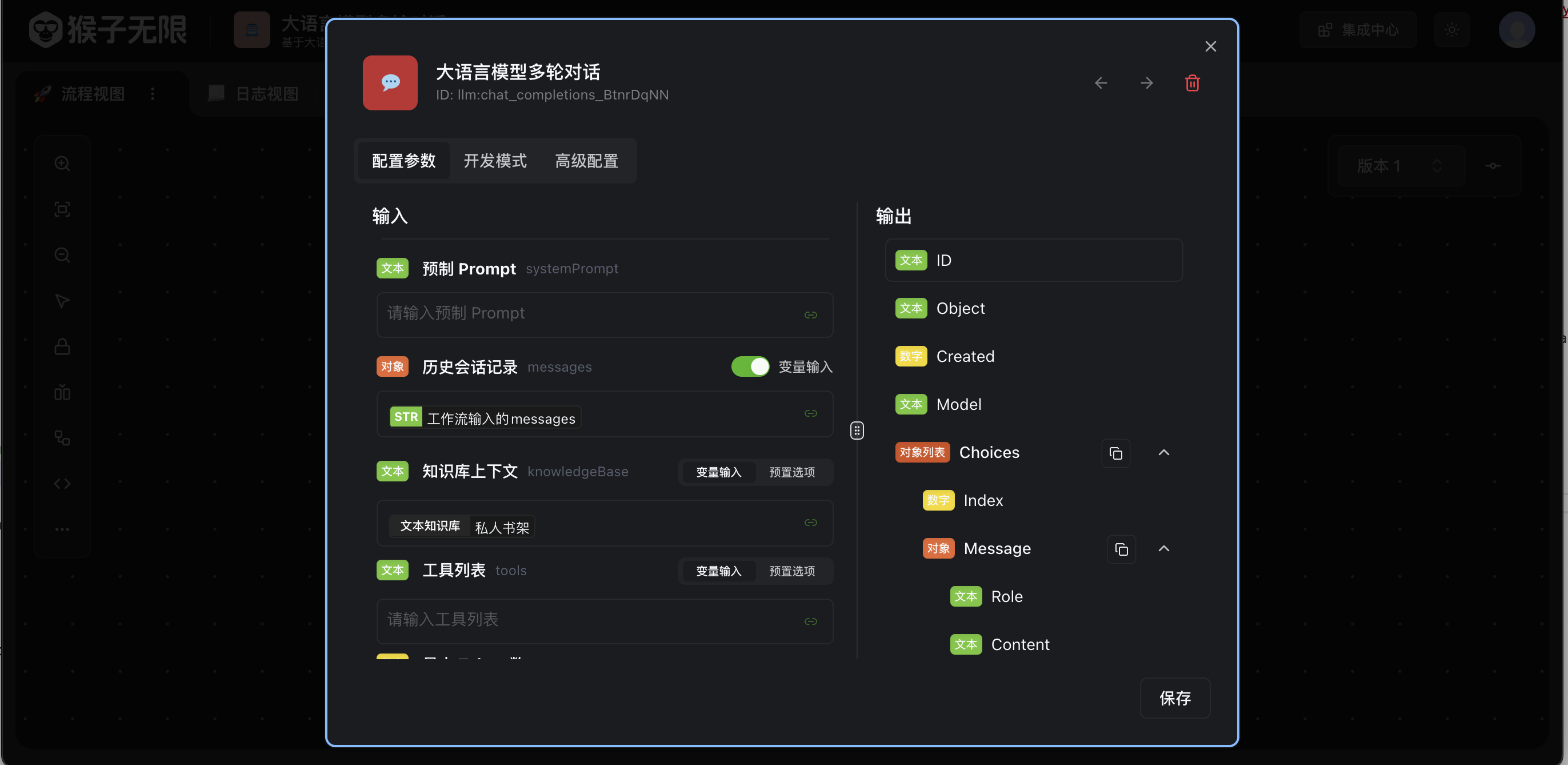
Using in Large Language Model Conversations
In the large language model multi-turn conversation tool, click Edit, select the text dataset we just created in the Knowledge Base Context and click save.
Copy the CURL command from the integration center button in the upper right corner of the workflow details and run it in the terminal:
curl -X POST 'http://localhost:2048/v1/chat/completions' \--header 'Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxx' \--header 'Content-Type: application/json' \--data-raw '{ "model": "xxxxxxxxxxxxxxxxxxx", "messages": [{"role": "user", "content": "What is this book about?"}], "stream": false}'You can see the response from the large language model:

Check the logs to see that the large language model called the private data search tool:
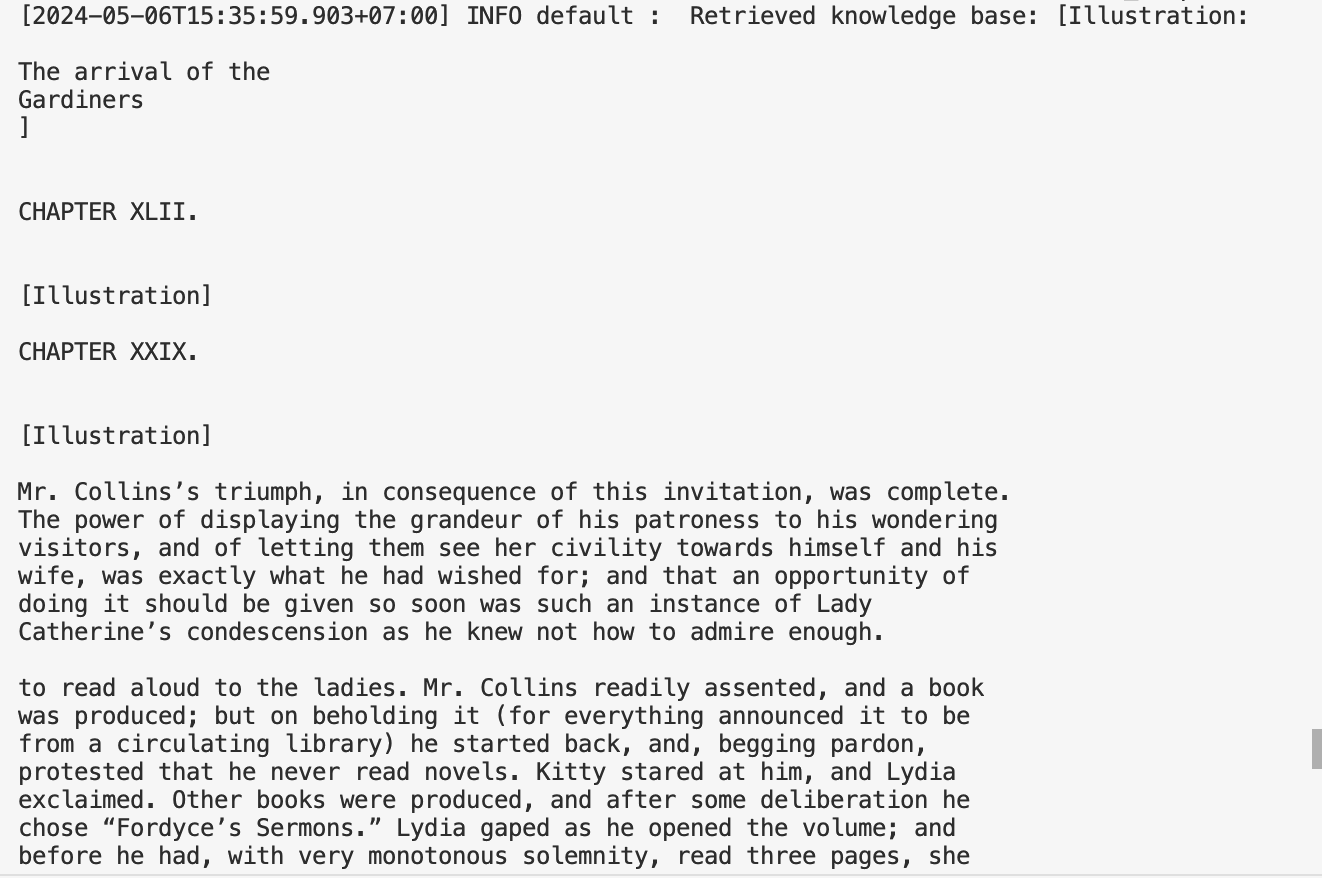
Note: The quality of the large language model’s response depends on the quality of the recalled vectors and the capabilities of the large language model itself.